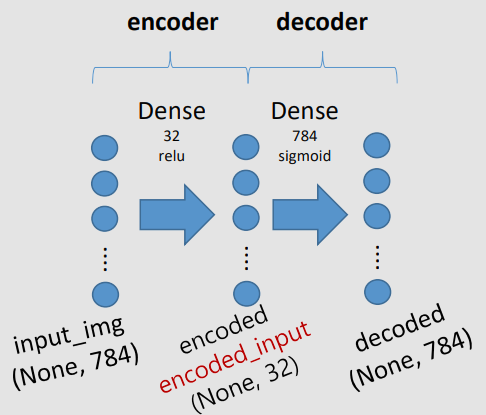
Encoder는 입력을 다른 형태(representation)으로 변환한다고 AE에서 알았다. VAE는 latent space에 고정된 벡터로 encode하는 것이 아니라, distribution으로 encode한다.
GAN: Generative Adversarial Network
decoder(generator)가 실제적인 fake images를 생성한다. 생성된 이미지를 descriminator가 실제 mnist 이미지에 기반해 구별한다. 서로 상호작용하면서 generator는 점차 실제 이미지에 가깝게 가짜 이미지를 생성하고, 이를 descriminator는 다시 학습한다.
지금까지 CNN, RNN 등 어떤 알고리즘이 있고, 어떻게 동작하는지 알아보았다. 이제 주어진 과제에 맞는 알고리즘을 선택하는 방법, 성능 평가하는 방법, 개선하는 방법에 무엇이 있고 어떻게 판단하는지 알아보겠다. 알고리즘을 올바르게 사용하는 방법론(methodology)의 간단한 예시는 다음과 같다. 1) 문제에 기반해 오차측정법과 목표오차측도를 결정 2) 성과추정을 포함한 end-to-end pipeline 확립 3) 단계별 개선효과 확인 수단 마련 4) 추가적인 데이터수집, 초매개변수 조정, 알고리즘 수정 등을 반복해서 시도
위의 예제처럼 member function으로 overloading하면 굳이 friend 키워드를 사용하지 않아도 구현할 수 있다.
Comparison Members
using Bracket Notation
Static class member functions
intString::HowMany(){returnnum_strings;}
각 객체에 관계 없이 class 전체에 대해 작용하는 함수이다. 당연히, static data members만 사용한다.
Further assignment operator overloading
String(constchar*s)String&String::operator=(constchar*s){delete[]str;len=std::strlen(s);str=newchar[len+1];std::strcpy(str,s);return*this;}Stringname;chartemp[40]="OOP";name=temp;// use constructor => assignment operator
본래 상단의 생성자를 사용할 경우에는 type conversion으로 임시로 String 객체가 만들어서 name에 복사한 후, 사용된 임시 객체를 제거한다. assignment operator를 사용하면 이러한 번거로운 과정 없이 곧바로 String 객체를 생성할 수 있다. 그러나 항상 constructor에서 new를 사용했다면 delete하는 것을 잊지 말라.
이렇게 String의 모든 동작을 문제 없이 구현했다면, String 객체는 built-in variable처럼 사용할 수 있다. 이제 String을 사용한 보다 상위의 객체에서는 String 객체의 복잡한 내부 구현을 신경쓰지 않아도 되는 것이다.
객체를 생성할 때, 특정 member data을 원하는 값으로 초기화하고 싶다면 initializer list를 사용할 수 있다. 만약 어떤 member data를 const로 선언했다면, 생성 이후에는 바꿀 수 없기 떄문에 initializer list를 사용해 초기화해줘야만 한다. 또한, member data 선언할 때 초기화한 값과 생성자에서 초기화하 값이 충돌할 수 있다. 이런 경우에는 생성자에서 초기화한 값을 우선으로 한다.
Questions?
Q1. nonmember / member / friend function의 정의가 헷갈립니다. A1.
Encoder는 입력을 다른 형태(representation)으로 변환한다. 일반적으로 compressed representation을 찾는 것을 말한다. 이를 위해 좋은 특징(features)을 추출해야한다. Features는 classify와 reconstruct에 쓰이기 때문에 가능한 많은 정보를 담아야 한다. 좋은 Encoder는 효과적인 latent space representation을 도출한다. encoder vector라고도 부른다.
AutoEncoder(AE)는 주어진 data에 맞게 encoder가 학습하는 것을 말한다.
// What default copy constructor does: shallow copyString::String(constString&s){str=s.str;len=s.len;}Stringmotto("HOHO");Stringditto(motto);Stringmetoo=motto;Stringalso=String(motto);String*pstring=newString(motto);
위 코드에서는 copy constructor가 metoo는 motto의 주소를 가리키는 shallow copy를 수행한다. motto와 metoo의 destructor가 동작하면, 이미 해제된 메모리를 참조하는 metoo의 destructor에서 core dump가 발생하게 될 것이다.
// Fixing the Problem by Defining an Explicit Copy ConstructorString::String(constString&st)// copy constructor{len=st.len;str=newchar[len+1];std::strcpy(str,st.str);num_strings++;cout<<num_strings<<": \""<<str<<"\" object created\n";}
위와 같이 copy constructor을 수정하여 deep copy를 수행해야 한다.
Assignment Operators
Copy Constructor와 마찬가지로, default로 shallow copy를 지원하기 때문에 별도로 구현해줄 필요가 있다.
String&operator=(constString&st);String&String::operator=(constString&st){if(this==&st)// object assigned to itselfreturn*this;delete[]str;len=st.len;str=newchar[len+1];std::strcpy(str,st.str);return*this;}
순환신경망(recurrent neural networks, RNN)은 순서가 있는 일련의 값들, 즉 순차열(sequence)을 처리하도록 특화된 신경망이다. grid 형태에 특화된 CNN처럼, 가변 길이의 입력을 받을 수 있다. 각 순환(cycle)마다 어떻게 입출력 크기를 조정하고, 가중치를 공유/수정하는지 알아보겠다. Graves, 2012
10.1 Unfolding Computational Graphs
RNN 모델을 입출력 연산이나 손실함수를 계산 그래프로 표현할 때, 순환/재귀를 통해 반복구조가 나타난다. 이를 수식으로 표현하면 점화식(reurrence formula)로 나타난다. 이는 모든 시간단계(cycle)에서 동일한 전이 함수와 동일한 매개변수를 적용한다는 의미이다.
10.2 Recurrent Neural Networks
동일한 함수와 매개변수를 반복구조에 적용시킬 때, 각 cycle 간의 연결을 조직하는 두가지 방법이 존재한다. 1) 은닉 대 은닉 순환 연결 : 일정한 cycle이 지난 후의 출력이 곧 RNN의 출력이다. 훈련 비용이 높다는 단점이 있다. 2) 출력 대 은닉 순환 연결 : 출력 단위에서 누락된 정보로 인해 표현력이 약하다. 대신 각 cycle을 병렬화할 수 있다. 위의 방법들처럼 각 cycle마다 출력을 산출하지 않고, 오직 하나의 출력만을 산출하는 방법도 존재한다. 3) 은닉 간 순환 연결을 통해 하나의 출력을 산출 : 중간 cycle에서 출력을 산출하지 않기 때문에 자연히 은닉층 간의 연결만이 가능하다.
10.3 Bidirectional RNNS
양방향 순환 신경망은 현재의 값을 이해하기 위해 미래의 값도 알아야하는 특수한 응용 사례를 위하여 고안되었다. 음성 인식 과제에서의 연음법칙이 그 예시가 될 수 있겠다. 입력 sequence의 시작 부분부터 나아가는 시간순 RNN과 마지막부터 돌아오는 역시간순 RNN이 결합되어, 이전 자료와 다음 자료를 모두 의존하되 현재 시점 근처의 자료에 가장 민감하도록 구현되었다.
한편, 가변 길이의 입력 순차열을 가변 길이의 출력 순차열로 사상할 필요가 있다. 입력과 출력의 길이가 서로 다른 데이터가 대부분이기 때문이다. RNN은 1) Encoder-Decoder와 2) sequence-to-sequence 두 가지 구조를 채택할 수 있다.
10.5 Deep Recurrent Networks
RNN의 각 cycle은 크게 세가지 연산을 수행한다. 1) 입력에서 은닉 상태 2) 현재 cycle 은닉 상태에서 다음 cycle의 은닉상태 3) 은닉 상태에서 출력 이들은 각각 MLP에서 층 하나로 표현되는 행렬 변환과 같은 연산을 수행한다. 따라서 각 연산을 하나의 층이 아닌 여러 층으로 바꾼다면 보다 깊은 신경망을 만들 수 있다.
10.6 Recursive Neural Networks
재귀 신경망은 순환신경망의 응용 중 하나이다. 사슬 형태의 RNN와 다르게 tree 형태로 구성되어 있다. 재귀 신경망의장점은 계산 비용이 입력 sequence 길이에 비례(O(r))하는 RNN과 달리 O(log r)이라는 것이다. 문제는 어떤 형태의 tree를 사용해야하는지 정해져있지 않다는 것이다. 가장 단순한 균형이진트리나, 구문분석기가 산출하는 parse tree 혹은 모델이 직접 적합한 트리 구조를 추론하도록 제안되어 왔다.
10.7 The ChaLong-Term Dependencies
여러 단계에 걸쳐서 전파되는 기울기가 소멸하거나 폭발하는 장기의존성 문제는 주로 단기 상호작용에 주어지는 가중치보다 지수적으로 작은 가중치들이 장기 상호작용에 주어질 때 발생한다. 단기적으로 아주 작은 변동에 장기적인 패턴이 가려지기 때문이다. 이를 해결하기 위해 고안된 접근방식들을 앞으로 살펴보겠다.
10.8 Echo State Networks
신경망이 출력 가중치들만 학습하도록 고안된 방식이다.
10.9 Leaky Units and Other Strategies for Multiple Time Scales
여러 시간 단위(time scale)에서 작동하도록 모델을 구성하는 것이다. 모델의 일부는 조밀한(fine-grained) 단위에서 세부사항들을 처리하고, 또 다른 일부는 성긴(coarse) 시간 단위에서 정보가 잘 전달되도록 동작하는 것이다. 이를 위해 서로 다른 시간 상수를 가진 leaky unit이 고안되었다.
10.10 The Long Short-Term Memory and Other Gated RNNs
실제 응용에서 가장 효과적인 순차열 모델은 게이트 제어 RNN(gated RNN)이다. LSTM이나 gated recurrent unit 등이 이에 속한다. leaky unit과 같은 가중치들이 cycle을 돌면서 모델에 의해 최적화된다. 예컨데, LSTM은 gate 역할을 하는 은닉층이 자기 자신의 가중치를 제어하여 time sacle을 동적으로 변하게 한다.
10.11 Optimization for Long-Term Dependencies
확률적 경사하강법을 적용한 LSTM은 최적화하기 좋은 모델을 설계하는 것이 강력한 최적화 알고리즘을 설계하는 것보다 훨씬 쉽다는 경험법칙을 충족하는 예이기도 하다.
10.12 Explicit Memory
이제 신경망은 암묵지 영역에서 꽤 잘 동작하는 것 같다. 그러나 오히려 명시적인 사실(fact)를 잘 기억하지 목한다. 이는 인간의 작업기억(working memory)에 해당하는 구조가 부재하기 때문이다. 명시적 기억 부재를 보완하기 위해 attention 매커니즘과 같은 전략이 발견되었다.
Questions
Q1. 10.2에서 소개된 세가지 구조를 충분히 이해하지 못했습니다. 은닉-은닉 연결이 강력한 이유와 출력-은닉 연결이 병렬화가 가능한 이유를 모르겠습니다. A1.
합성곱망(convolutional networks; LeCun, 1989) 또는 합성곱 신경망(convolutional neural network, CNN)은 격자 형태(grid-like topology)로 배열된 데이터를 처리하는 데 특화된 신경망이다. 어떤 CNN 구조가 어떤 상황에 좋은지보다, 어떻게 CNN이 구성되는지 위주로 정리하겠다.
9.1 The Convolution Operation
두 함수를 합성곱 (f*g)(x)할 때, 첫 인수(f)를 입력이라고 부르고, 둘째 인수를 kernel이라고 부른다. 출력 결과를 feature map이라고도 부른다. 합성곱은 단순한 덧셈 혹은 곱셈 하나가 아니라, 확률곱의 합산처럼 생각하면 조금 이해하기 편하다.
예를 들어, \((1,2,3)*(4,5,6) = (4, 1*5+2*4, 1*6+2*5+3*4, 2*6+3*5, 3*6) = (4, 13, 28, 27, 18)\) 이 되는 것이다.
위의 합성곱 개념을 딥러닝에서 활용할 때, kernel에는 확률밀도함수를 넣는다. kernel을 이동평균으로 해석하면, 원본 데이터을 smoothing한 효과가 난다. 이는 시계열 데이터나, 시각 데이터에 적용될 수 있다.
9.2 Motivation
합성곱 신경망이 유용한 까닭은 다음 세가지 이유로 설명할 수 있다. 1) sparse interaction : 본래 각 계층에서 필요한 연산의 크기는 (input*output)이다. 그러나 작은 kernel만으로 원하는 feature을 추출할 수 있을 떄, 필요한 연산의 크기는 (kernel*output)뿐이다. 물론 해당 계층에서는 직접적으로 연결되지 않은 노드를 학습할 수 없지만, 보다 심층에서는 간접적으로 영향을 받을 수 있다. 이를 보장하기 위해 간격(stride)을 주거나 pooling 구조로 합성곱망을 구성한다. 2) parameter sharing : 모든 입력에 동일한 kernel이 사용된다. 계산비용과 메모리 비용 모두 획기적으로 감소한다. 3) equivariant representations : 입력이 다소 변하더라도 동일한 출력을 보장하는 개념이다. 예컨데, CNN은 이미지의 위치를 이동시켜도 원하는 feature을 동일하게 잡아낸다. 단, 회전한 경우에는 불가능하다.
9.3 Pooling
pooling은 합성곱의 결과로 도출된 활성화 값을 이웃 출력들의 요약통계량(summary statistics)로 대체한다. 일반적으로 max, average, $$L^2&& Norm, weighted average 등이 쓰인다. pooling을 통해 입력의 작은 변화에 대해 특징이 불변(invariant)하도록 할 수 있다. 더불어 계산비용을 낮추고, 과적합을 방지해 일반화 성능을 향상시키는 효과가 있다.
9.4 Convolution and Pooling as an Infinitely Strong Prior
Infinitely Strong Prior(무한히 강한 사전확률분포)란 일부 매개변수에 0을 할당하여 절대로 영향을 끼치지 못하게 강요하는 분포이다. 확률밀도가 얼마나 조밀한지 곧, 분산과 반리례하는 척도가 strong과 weak이다. 합성곱 신경망과 pooling은 고정된 kernel과만 상호작용하기 때문에 무한히 강한 사전분포라고 볼 수 있다.
9.5 Variants of the Basic Convolution Function
지금까지 표준적인 이산합성곱 연산을 수학적 관점으로 알아보았다. 그러나 딥러닝에서 실제로 쓰이는 합성곱 함수는 수식이 다소 다르다. 먼저, 각 계층에서 각기 다른 feature를 추출하는 여러 합성곱이 병렬로 연산된다. 둘째로, 계산 비용을 줄이기 위해 정해진 stride만큼 뛰어넘으면서 출력하는 하향표본화(downsampling)가 있다.
9.6 Structured Outputs
합성곱의 결과로 특정 값 하나가 아닌 tensor로 출력할 수 있다. 다차원 구조적 객체인 tensor는
9.7 Data Types
입력과 출력의 크기를 가변적으로 할 수 있다는 것도 합성곱 신경망의 장점이다. 예를 들어, width와 height가 다른 여러 이미지들이 있을 때, 동일한 kernel을 사용해도 합성곱 알고리즘을 실행하는데 전혀 문제가 없다. 다만 고정된 크기의 출력을 산출하고 싶다면, pooling이나 stride를 조정해야하긴 할 것이다. 다만, 위의 예시처럼 입력의 크기가 달라도 처리할 수 있는 것은 관측값의 종류는 동일할 때만 가능하다.
9.8 Efficient Convolution Algorithms
합성곱 연산을 그대로 하는 것보다, 퓨리에-역퓨리에 변환으로 계산하는 것이 훨씬 빠르다.
9.9 Random or Unsupervised Features
CNN에서 계산 비용이 가장 많이 드는 부분은 합성곱이 아닌, 도출된 feature의 학습이다. 지도 학습을 위해 경사하강법을 수행하려면, 신경망 전체에 대한 순전파와 역전파가 이뤄져야 하기 때문이다. 따라서 지도 학습을 하지 않고 합성곱 kernel을 수정하는 전략이 연구되었다. 일반적으로는 연구자가 직접 kernel을 수정하고 했다. 놀랍게도 무작위로 kernel을 초기화할 때도 잘 동작하곤 한다. 또, 신경망 전체가 아닌 각 층마다 greedy 방식으로 훈련하는 방법도 있다. 그러나 이러한 방식은 데이터가 적고 계산 능력이 낮던 과거에 필요했던 전략으로, 현재는 대부분 완전한 지도학습을 통해 학습한다.
9.10 The Neuroscientific Basis for Convolutional Networks
CNN 역시 뇌과학에서 대단히 많은 영감을 받았다. 시각이 받아들이는 정보를 1차 시각피질에서 처리하는데, 이는 단순세포와 복합세포로 이루어져 있다. 각각 activation과 pooling에 영향을 주었다. 또한, equivariant representations 개념 역시 ‘할머니 세포’에서 영향을 받았다. 그러나 우리 뇌가 이미지를 받아들이는 방식보다 한참 낮은 수준에서 CNN은 동작한다. 아직도 발전할 여지가 많다.
9.11 Convolutional Networks and the History of Deep Learning
그럼에도 CNN은 딥러닝 영역에서 가장 대표적인 모형이다. 실제로 딥러닝을 수행할 수 있기 전에도 역전파로 학습을 성공한 최초의 딥러닝 모델이다. grid-like topology의 데이터들에 적합하고, 입력이나 출력의 가변크기를 보장한다는 장점이 있다. 이는 2차원 이미지에 특히 유용하다. 1차원 자료들에 유용한 순환신경망은 어떻게 구성되어 있는지 다음 챕터에서 살펴보겠다.
Questions
Q1. I don’t understand why random filters work so well in 9.9. Is there a hypothesis that explains this? A1.
Q2. While the attention strategy mentioned in 9.10 was successfully accepted in natural language processing, why did it not work well in visual models? A2.
전하의 이동을 방해하는 소자. 가장 간단한 형태의 Passive 소자이다. Passive 소자란, 에너지를 생성하지 못하고 소모만 하는 소자를 말한다.
전류(\(i = \frac{dq}{dt}\))의 통과를 방해하기 때문에 에너지(\(v=\frac{dw}{dq}\))를 필요로 한다. 즉, 전류와 저항이 클수록, 전압이 강화된다. 강화되는 정도에 따라 선형/비선형 저항체로 나뉜다. 선형 저항체의 경우, 전압은 전류에 대해 비례상수 R(저항값)로 1차 비례한다.
Ohm’s Law
V-I 관계가 근사적으로 선형인 경우, 옴의 법칙은 유효하다. 전압과 전류, 저항값의 관계는 \(V=IR\)을 따르며, 저항의 단위는 Ω(Ohm)이다.