ch1. AI 작업환경 구성 ch2. 데이터 획득 ch3. 데이터 구조 확인 ch4. 기초 데이터 ch5. 데이터 이해 ch6. 데이터 전처리 ch7. AI 모델링 필수 개념 이해 ch8. 지도학습으로 AI 모델링 ch9. 비지도학습으로 AI 모델링 ch10. 모델 성능 향상 ch11. 실습 - 렌탈고객 해지 여부 예측 ch11.1 데이터 처리 ch11.2 데이터 이해 ch11.3 데이터 전처리 ch11.4 모델링과 평가
이래저래 병행하는 일을 처리하다보니.. 어느새 하루 밖에 안 남았다. 남은 40시간 야무지게 사용해보자.
ch1. AI 작업환경 구성 ch2. 데이터 획득 ch3. 데이터 구조 확인 ch4. 기초 데이터 ch5. 데이터 이해 ch6. 데이터 전처리 ch7. AI 모델링 필수 개념 이해 ch8. 지도학습으로 AI 모델링 ch9. 비지도학습으로 AI 모델링 ch10. 모델 성능 향상 ch11. 실습 - 렌탈고객 해지 여부 예측 ch11.1 데이터 처리 ch11.2 데이터 이해 ch11.3 데이터 전처리 ch11.4 모델링과 평가
앞으로 3일에 걸쳐 예제를 쭉 따라가며 실습 및 개념 복습하겠다. 토요일(7/13)까지 3일 남은 만큼, 하루에 챕터 3개 정도 진도를 나가면 되겠다.
그럼, 시작하자.
ch1. AI 작업환경 구성
일반적으로 Jupyter나 Colab을 주로 사용한다. 그러나 AICE는 시험을 위해 독자적인 AIDU 도구를 제공한다. AICE 홈페이지 > AICE 실습 > 나의 프로젝트
ch2. 데이터 획득
라이브러리 설치를 위한 명령어는 다음과 같다.
!pipinstall<library>import<library>as<alias>
주로 사용하는 라이브러리는 2가지이다. 1) numpy : n차원 배열 객체인 ndarray를 처리함
np.array()
2) pandas : 1차원 배열인 Series, 행(row)과 열(column)으로 구성된 2차원 테이블인 DataFrame을 처리함
bjho@BJH:/mnt/c/Users/bjh17/Projects$ cd code
bjho@BJH:/mnt/c/Users/bjh17/Projects/code$ cd 0-Education/
bjho@BJH:/mnt/c/Users/bjh17/Projects/code/0-Education$ cd SystemProgramming/
bjho@BJH:/mnt/c/Users/bjh17/Projects/code/0-Education/SystemProgramming$ ls
Dive-into-Systems-ch3
bjho@BJH:/mnt/c/Users/bjh17/Projects/code/0-Education/SystemProgramming$ cd
Dive-into-Systems-ch3/
bjho@BJH:/mnt/c/Users/bjh17/Projects/code/0-Education/SystemProgramming/Dive-into-Systems-ch3$ ls
a.exe badprog.c segfault.c
광고와 트레킹은 여러가지 불안을 유발합니다. 프라이버시, 보안, 웹페이지 성능, 불편한 사용경험 등입니다. 이에 따라, 브라우저 공급자와 사용자 모두 특정 유형의 콘텐츠를 차단하는 content blocking에 대한 요구가 증대되고 있습니다. 저 같은 경우 adblock과 brave를 사용해보았습니다
그렇다면 이러한 광고와 트레킹을 어떻게 막고 있었을까? 자바스크립트 코드나 URL의 패턴을 기반으로 rule을 만들어 filter list로 거른다. 그러나 새로운 침해에 대응하기에는 오래 걸리는 반면, 오래된 침해방식은 곧 유효하지 않습니다. 실제로 제가 복무했던 해군사이버작전센터는 유해 ip와 해킹메일을 black list 룰로 차단했는데, 주기적으로 과거 차단 목록을 검토하고 없애주어야 했습니다.
그러나 더 큰 문제는 도메인을 바꾸거나 first-party에서의 침해, javascript를 적절히 난독화하는 전형적인 회피 수단에도 쉽게 뚫린다는 것입니다. 이에 따라 machine learning을 활용한 blocking도 연구되었으나 여전히 scalability와 accuracy 문제들이 있습니다.
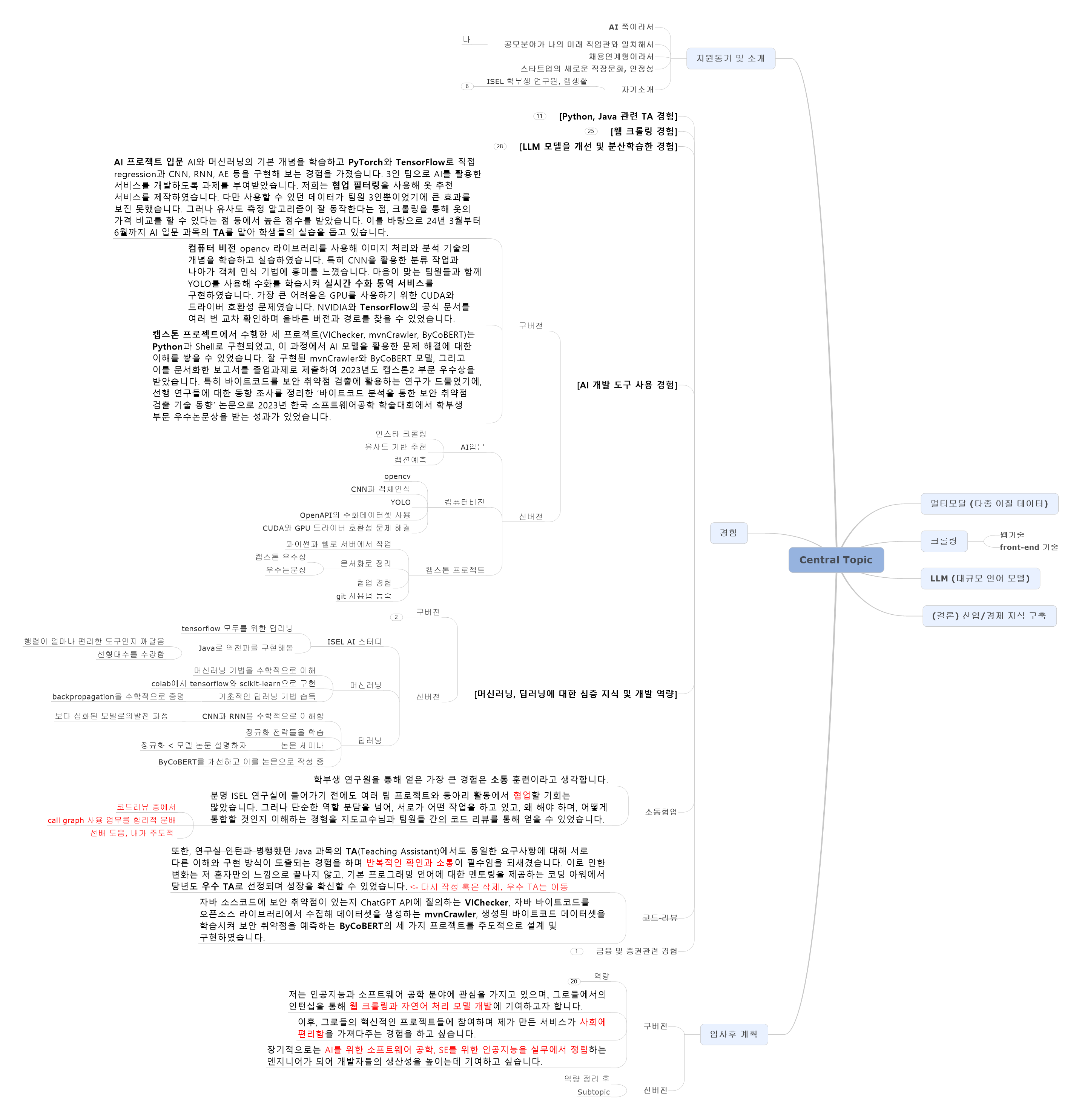
지원동기 및 소개 저는 백과사전을 좋아하는 어린이였습니다. 호기심이 많아 새로운 정보를 습득하는 것에 즐거움을 느끼며, 납득이 안 되는 용어나 논리가 있다면 해소가 될 때까지 파고들고는 합니다. 그런 저에게 코딩 과제는 하나하나가 재미있는 도전이었습니다. 주어진 문제를 해결하도록 설계하고, 그대로 구현하는 과정이 너무나 즐거워서 팀플 과제에서도 최대한 구현을 독점하려 했었습니다. 그렇게 책 속의 작은 과제들에 매달려 있던 저를 변화시킨 것은 Intelligent Software Engineering Lab(ISEL)에서의 학부생 연구원 경험이었습니다. ISEL은 인공지능에 소프트웨어 공학 기법을 적용하고, 소프트웨어 공학의 도구로 AI를 활용하는 방법을 연구하는 연구실입니다. 저는 랩실에서 처음으로 혼자 힘으로는 주어진 시간 내에 달성할 수 없는 과제를 마주했습니다. 자바 오픈소스 프로젝트에 존재하는 취약점을 ChatGPT가 검출할 수 있는지 확인하는 VIChecker라는 프로젝트였습니다. 이 팀 프로젝트에서 저는 ChatGPT 출시 이후에 오픈소스 프로젝트에서 유의미하게 수정된 자바 파일을 git을 이용해 추출하고, 이들을 정해진 프롬프트에 따라 ChatGPT API를 사용해 질의하는 역할을 맡았습니다. 그러나 정말 어려웠던 작업은, 오픈소스 코드를 ChatGPT가 올바르게 분석했는지 검증하는 일이었습니다. 팀원들은 각자 일정량의 코드를 담당해서 분석하며, 교차 검증을 위해 다른 팀원들을 빠르게 이해시키고 피드백을 받아야 했습니다. 또한, 이러한 오픈소스 코드 리뷰 과정을 통해 제가 얼마나 혼자만 이해할 수 있는 코드를 짜왔는지 알 수 있었습니다. 이러한 과정을 통해 협업이 단순한 업무 분담이 아니라, 서로가 어떤 작업을 하고 있고, 왜 해야 하며, 어떻게 나아갈 것인지 이해하는 것임을 알게 되었습니다. 이후, 코드 리뷰 경험을 더 많은 학생이 일찍부터 했으면 좋겠다고 생각해 실습 조교와 멘토링을 하며 도움을 주고자 했습니다. 랩실에서 AI를 활용한 더 많은 팀 프로젝트를 진행하며, 의사결정을 돕는 딥러닝 모델이 앞으로 필수적인 도구가 될 것으로 생각하게 되었습니다. 특히, 수많은 정보를 유용하게 소비하기 위해서는 텍스트뿐만 아니라 이미지나 비디오 같은 다양한 데이터 소스를 활용해야 합니다. 그로들에서 AI를 활용한 이미지 번역, 자동 영상 제작, 자동 회의록 작성, 추천시스템 등 다양한 서비스를 개발한 선배 전문가들과 소통하며 의사결정에 도움이 되는 멀티 모달 서비스를 개발하고 싶습니다.
인턴 직무 관련 경험 [Python, Java 관련 TA 경험] 저는 학부 시절 파이썬과 자바 과목을 수강하며 각 언어의 기본적인 문법과 자료구조, 파일 처리 방법을 배웠습니다. 또한 객체지향 적으로 설계하는 방법과 오픈소스 라이브러리를 사용하는 방법을 배웠고, 특히 자바에서는 gradle과 같은 빌드 도구를 활용하는 연습을 많이 할 수 있었습니다. 그 과정에서 소스코드의 문법으로만 발생하는 줄 알았던 에러들이, 라이브러리 버전이나 프레임워크 세팅과 같은 코드 외적인 부분에서 더 많이 나타난다는 것을 알게 되었습니다. 제각기 다른 이슈들이 다른 학생들에게도 발견되는 것을 보며, 저는 이것을 앞으로 개발자로서 경험하게 될 수많은 이슈를 미리 경험할 기회로 여겼습니다. 이후, 자바 과목에서 수강생들의 실습에서 발생하는 이슈를 대처하는 TA(Teaching Assistant)를 1년간 맡았습니다. 학생들이 주로 어려움을 느끼는 gradle과 spring의 첫 설치에서 발생한 에러들을 파악하고 해결책을 찾았습니다. 그뿐만 아니라 인터페이스와 예외 처리 클래스와 같은 객체지향 개념을 설명하면서 강의를 수강할 때보다도 프로젝트 설계에 대한 이해를 높일 수 있었습니다. 동시에 기본 프로그래밍 언어(C/C++, Java, Python)을 멘토링 하는 코딩 아워 TA를 1년 반에 걸쳐 맡으며 랩실에서 배웠던 코드 리뷰 방법을 학생들과 공유하고자 했습니다. 이러한 노력을 인정받아, 2023년도 코딩 아워 우수 TA로 선정되었습니다. [웹 크롤링 경험] 저는 대규모 언어모델(LLM)을 학습시키기 위한 데이터셋을 수집하는 동적 웹크롤러, mvnCrawler를 selenium과 python으로 구현하였습니다. 바이트코드를 언어모델에 학습시키는 선형 연구가 부재하여, 독자적인 데이터셋을 생성하기 위해 제작하였습니다. 크롤링 대상은 자바 오픈소스 라이브러리가 담긴 maven 저장소입니다. 1000개 이상의 프로젝트와 각 프로젝트의 버전들의 정보를 수집하기 위해 ‘프로젝트/버전’ 경로를 트리로 저장하여 순회하였는데, maven 자체 오류로 dangling tree가 만들어져 몇몇 프로젝트 내에서 무한 루프가 돌아가는 이슈가 있었습니다. 이를 해결하기 위해 무한 루프를 탐지하면, 잠시 크롤러를 멈추고 순회할 경로를 담은 큐에서 문제가 되는 경로를 삭제하는 스크립트를 작성하였습니다. 또한, 일부 오픈소스의 버전에 당연히 있을 것이라 가정했던 소스코드와 같은 파일이 부재하여 에러가 발생하기도 했습니다. 실무에서는 예측하지 못한 예외들이 있을 수 있단 것을 실감하고, 섣불리 예외 처리를 마쳤다고 안심해서는 안 된다는 교훈을 얻었습니다. [LLM 모델 개선 및 분산학습 경험] mvnCrawler로 생성한 데이터셋을 학습하도록 BERT를 개선한 ByCoBERT 모델을 제작하였습니다. 그러나 BERT에 비해 상당히 작은 데이터셋을 사용하였기에 과적합을 막으려면 계층과 파라미터 개수를 줄여 모델의 수용력을 낮춰야 했습니다. 이렇게 작은 데이터셋과 모델로 과연 충분한 효과를 볼 수 있을까? 라는 의문이 들었습니다. 이를 해소하기 위해 CodeBERT, JavaBERT, DexBERT 등 프로그래밍 언어를 학습시킨 선행 연구를 조사하였고, 자연어에 비해 정칙성이 있는 코드는 상대적으로 작은 크기의 데이터셋과 모델로도 효과가 있다는 실증 결과를 얻을 수 있었습니다. 한편, pre-training 과정에서 GPU 자원 부족으로 인해 모델이 학습 도중 중단되는 문제가 발생했습니다. 저는 최적화 알고리즘을 Adam에서 SGD로 다소 낮추고, PyTorch가 제공하는 DDP(Distributed Data Parallel)를 적용하여 4개의 GPU를 모두 사용하도록 코드를 수정하였습니다. 그러나 사전 학습 결과는 기대와 달리, MLM(Masked Language Modeling)과 NSP(Next Sentence Prediction) 모두 무의미한 토큰을 예측하였습니다. 원인은 mvnCrawler로 생성한 데이터셋을 충분히 전처리하지 않고 학습시켰기 때문이었습니다. 불필요한 토큰들을 제거하는 튜닝 과정까지 모두 거친 ByCoBERT 모델은 예측 성능이 상용모델인 spotbug보다 우수한 f1-score 성능을 보여 공동 저자로 정보과학회논문지에 논문 을 제출하고 심사를 기다리고 있습니다. [AI 개발 도구 사용 경험] AI 프로젝트 입문 과목에서 머신러닝과 딥러닝의 기본 개념을 학습하고, tensroflow로 Jupyter 환경에서 regression부터 CNN, RNN, AE 등을 직접 구현했습니다. 또한, 3인 팀으로 협업 필터링을 사용해 옷 추천 서비스를 제작하였습니다. 다만 사용할 수 있던 데이터가 팀원 3인뿐이었기에 큰 효과를 보진 못했습니다. 그러나 유사도 측정 알고리즘이 잘 동작한다는 점, 크롤링을 통해 옷의 가격 비교를 할 수 있다는 점 등에서 높은 점수를 받았습니다. 이를 바탕으로 24년 3월부터 6월까지 AI 입문 과목의 TA를 맡아 학생들의 실습을 돕고 있습니다. 컴퓨터 비전 과목에서 opencv 라이브러리를 사용해 이미지 처리와 분석 기술의 개념을 학습하고 실습하였습니다. 특히 CNN을 활용한 분류 작업과 나아가 객체 인식 기법에 흥미를 느꼈습니다. 마음이 맞는 팀원들과 함께 YOLO를 사용해 수화 영상을 학습시켜 실시간 수화 통역 서비스를 구현했습니다. AI-Hub에서 공개한 수어 데이터셋을 활용하였습니다. GPU를 사용하기 위한 CUDA와 드라이버 호환성이 맞지 않아 시작이 어려웠습니다. NVIDIA와 TensorFlow의 공식 문서를 여러 번 교차 확인하며 올바른 버전과 경로를 찾으며 해결할 수 있었습니다. [머신러닝, 딥러닝에 대한 심층 지식 습득] 제가 소속된 랩실은 인공지능과 소프트웨어공학을 접목하는 연구를 진행하고 있기 때문에, 소속원 모두가 지도교수님과 AI 스터디를 진행합니다. ‘모두를 위한 딥러닝’ 강의를 함께 시청하며 돌아가며 세미나를 진행하였습니다. 저는 특히 역전파 과정에 관심을 가졌고, 자바로 3층 신경망의 순전파와 역전파를 구현해 보았습니다. 이전까지는 행렬 계산에 익숙하지 않았으나, 이 과정에서 행렬이 얼마나 편리한 도구인지 느끼고 선형대수학을 수강했습니다. 머신러닝 과목에서는 회귀, 분류, 밀도 추정, PCA 등의 머신러닝 개념을 수학적으로 이해하고, colab 환경에서 tensorflow와 scikit-learn 라이브러리들이 제공하는 kNN, RBFN, dse, pca 등의 함수들을 실제로 구현해 보면서 정말로 알고 있음을 확인했습니다. 또한, 딥러닝 개론 과목을 수강하며 CNN과 RNN, Representation 학습 등을 수학적으로 이해하고, 앞의 모델들이 실무에서 사용되기 위해 어떤 정규화 전략들이 존재하는지 학습하였습니다. 나아가 Attention, BERT, Explainable AI, Auto-Encoding 등의 주요 논문들에 대한 세미나를 진행했습니다. 특히, Understanding Deep Learning Requires Rethinking Generalization 논문은 앞에서 배워왔던 정규화 전략들도 분명 중요하지만, 모델 자체의 성능이 일반화 성능에 영향이 크다는 사실을 밝혀 큰 인상을 남겼습니다. 본 논문에서 밝힌 너무 커다란 모델은 학습이 아닌 암기를 한다는 지적은 어떻게 해결할 수 있을지 고민이 되었습니다.
입사 후 계획 지원하는 직무인 멀티모달 분석 기반 딥러닝 모델 개발을 위해 다음의 역량을 키웠습니다. 파이썬과 자바에서의 TA 경험을 통해 기본 문법부터 객체지향 설계와 빌드 도구 사용까지 능숙하게 다루며, 다양한 이슈를 해결할 수 있습니다. 동적 웹 크롤러를 직접 구현하고, 이를 통해 수집한 데이터셋을 전처리할 수 있습니다. 텍스트 데이터만이 아니라 영상 데이터에 대한 정규화 역시 가능합니다. 또한, 목적에 맞게 LLM 모델을 개선하고 분산 학습을 적용하여 AI 모델의 학습 성능을 향상할 수 있습니다. 이외에도 다양한 AI 프로젝트 경험을 통해 머신러닝과 딥러닝의 이론과 문제해결 능력을 습득하였습니다. 이러한 역량을 바탕으로, 그로들에서 경제/산업 뉴스 기반 지식 모델을 구축하겠습니다. 나아가, AI를 활용해 사회에 편리함을 가져오는 다양한 솔루션들을 만들고 싶습니다. 다양한 AI 서비스를 제작한 선배들이 있는 그로들은 제 꿈을 향해 나아갈 최적의 자리라고 생각합니다.
한화계열 스타트업, 그로들에 제출하기 위한 자소서를 작성 중이다. 이커머스 시장에서 생산성을 높일 수 있는 AI 솔루션을 개발하는 기업이다.
그로들의 요구사항을 정리하면 다음과 같다. “경제/산업 뉴스를 크롤링하여 요약할 수 있는 자연어처리/멀티모달 딥러닝 모델 개발” 만약 정규직으로 전환된다면, LLM과 Vision 쪽의 업무가 배정될 것이다. LLM은 summary, translation, document intelligence 등, vision은 문자인식, 객체인식, text/image-to-video 등이겠지. 모델 최적화나 분산학습 경험과 fine-tuning 경험자, 모델 개선 경험자도 찾고 있다. NLP에 필요한 데이터 수집 및 모델링도 경험한다면 우대사항이다. 상용 AI API와 tensorflow/pytorch와 같은 프레임워크에 대한 경험이 있다면 좋겠지. 또한, Linux/Unix와 Docker 환경을 주로 사용할 것이고, 협업(git, 코드리뷰)을 중요시하는 것으로 보인다.
한화계열 스타트업, 그로들에 제출하기 위한 자소서를 작성 중이다. 이커머스 시장에서 생산성을 높일 수 있는 AI 솔루션을 개발하는 기업이다.
그로들의 요구사항을 정리하면 다음과 같다. “경제/산업 뉴스를 크롤링하여 요약할 수 있는 자연어처리/멀티모달 딥러닝 모델 개발” 만약 정규직으로 전환된다면, LLM과 Vision 쪽의 업무가 배정될 것이다. LLM은 summary, translation, document intelligence 등, vision은 문자인식, 객체인식, text/image-to-video 등이겠지. 모델 최적화나 분산학습 경험과 fine-tuning 경험자, 모델 개선 경험자도 찾고 있다. NLP에 필요한 데이터 수집 및 모델링도 경험한다면 우대사항이다. 상용 AI API와 tensorflow/pytorch와 같은 프레임워크에 대한 경험이 있다면 좋겠지. 또한, Linux/Unix와 Docker 환경을 주로 사용할 것이고, 협업(git, 코드리뷰)을 중요시하는 것으로 보인다.
자, 위의 내용 중 초안에 들어가지 않은 것은? 1) fine-tuning 경험 2) 분산학습 경험 3) tensorflow/pytorch 자세히 쓸 것 4) 모델 개선 과정에서 겪은 어려움을 쓸 것 5) AI API 쓰면서 어려움은 없었나? 6) linux 서버에서 내가 무슨 일을 했지? 7) git 쓰면서 무얼 배웠지?
또한, 뭐가 부족하지? 8) 전반적으로 사실의 나열이지, 어떻게 왜 했는지 내용이 비어있다. 9) 동기가 부족하다 10) 입사 후 계획이 곧 떠날 사람처럼 느껴진다. 11) 경제학 입문 - 문장이 그냥 맘에 안든다. 필히 고칠 것.
이제, 2차 개정 시작! 직무 관련 경험 사항을 어떻게 바꿔야할까? 인턴 직무로 넣어야할 목록을 정리해보자. 1) 웹 크롤링 - 데이터셋 2) 자연어처리모델 - 분산학습, 모델 개선 3) python, java 4) 머신러닝/딥러닝 - 지식과 프레임워크 사용 경험 다음으로는 정규직에 도움될 요소를 넣어보자 5) git, linux 6) 코드리뷰 7) AI API
위의 목록에 대응하는 내가 한 것들을 나열해보자. 1) VIChcker : git, linux, AI API 2) mvnCrawler : 크롤러 3) ByCoBERT : 자연어처리모델 개선, 분산학습 4) TA : python, java, ai입문, 코드리뷰 5) 컴퓨터비전 : tensorflow, CNN, YOLO 6) ai 입문 : tensorflow, 주식예측(CNN, RNN, LSTM) 7) 머신러닝 : tnesorflow, 8) 딥러닝 개론 : pytorch, ByCoBERT_v2 9) 캡스톤 : 문서작업?